実データの解析(その7)
多変量解析・機械学習の実装に便利な言語・ソフトやサンプルスクリプト、解析例を紹介します。
スクリプト(6) Rによるクラスター分析(Ward法)
ヨーロッパ諸国の食料消費
※John Burkardt氏(フロリダ州立大学)のサイトのHARTIGAN Clustering Algorithm Datasetsにある"European foods"(file45.txt)をR入力用に整形して使用
※整形後のファイルはこちら。データはいくつかの食料品について、家庭での保有率(%)を示す(詳細は元データ参照)。
※データのオリジナルの出典は、John Hartigan,Clustering Algorithms,Wiley, 1975
※データの読込に際し、日本語のフォントの関係でエラーが生じる場合がある。また、分析結果の表示に際し、日本語が文字化けする(四角形のいわゆる豆腐になる)場合もある。これらの対処法は後述。
| cldata <- read.csv("efoods.csv", header=TRUE,
row.names=1) #食料のデータ読み込み cldis <- dist(cldata) #ユークリッド距離を計算 cl=hclust(d=cldis, method="ward.D2") #Ward法でクラスタリング plot(cl) #デンドログラムを表示 |
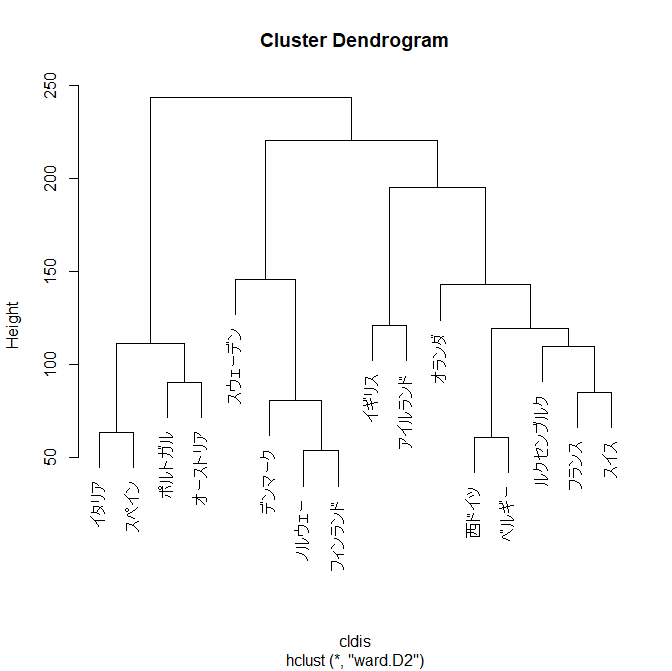
※データの読込に際し、日本語の文字コードの関係でエラーが生じる場合は、ファイルで用いている文字コードを明示的に正しく記述すると解決する可能性が高い。下記はShift_JISの場合。
| cldata <- read.csv("efoods2.csv", header=TRUE,
row.names=1, fileEncoding="Shift_JIS") |
UTF-8の場合は下記の通り。
| cldata <- read.csv("efoods2.csv", header=TRUE, row.names=1, fileEncoding="UTF-8") |
一方、分析結果の表示に際し、日本語が文字化けする(四角形のいわゆる豆腐になる)場合は、plot関数のオプションとして、用いるフォントファミリーを明示的に指定可能。 これで改善しない場合は、日本語のフォントをインストールすると改善する場合がある。例えば、Google Colaboratoryでは、入力ファイルの文字コードがShift_JISの場合、下記のようにすれば、正常に表示できた(2025年7月)。 なお、これでも改善しない場合、Google Colaboratoryとの接続を一旦切って、各種設定をリセットしてから、再度試すと改善することがある。
| system("apt-get install -y fonts-noto-cjk") #フォントのインストール cldata <- read.csv("efoods.csv", header=TRUE, row.names=1, fileEncoding="Shift_JIS") #食料のデータ読み込み(文字コードがShift_JISの場合) cldis <- dist(cldata) #ユークリッド距離を計算 cl=hclust(d=cldis, method="ward.D2") #Ward法でクラスタリング plot(cl, family="Noto Sans CJK JP") #デンドログラムを表示(フォントを指定) |
入力ファイルの文字コードがUTF-8の場合は、下記の通り。
| system("apt-get install -y fonts-noto-cjk") #フォントのインストール cldata <- read.csv("efoods.csv", header=TRUE, row.names=1, fileEncoding="UTF-8") #食料のデータ読み込み(文字コードがUTF-8の場合) cldis <- dist(cldata) #ユークリッド距離を計算 cl=hclust(d=cldis, method="ward.D2") #Ward法でクラスタリング plot(cl, family="Noto Sans CJK JP") #デンドログラムを表示(フォントを指定) |